Cómo empezar con un bot y acabar haciendo Business Intelligence
- Published on
- • 6 minutos
<strong>Disclaimer</strong>: Todo este post está basado en datos capturados <strong>hora a hora</strong>, con la pérdida
de información que eso conlleva.
Llevaba tiempo con ganas de desarrollar algo fuera del trabajo que tuviera que ver con bots. Ya que esto no era más que un pequeño experimento, decidí elegir Twitter como plataforma en la que dar 'vida' a mi bot.
Se pueden hacer muchos tipos de bots, pero en este caso consideré que hacer un bot sencillo era la mejor opción. La funcionalidad del bot es escribir tweets cada hora de datos con cierto interés, no responde a menciones ni piensa más allá de eso, pero escribe de forma automática.
El bot escribe dos tweets cada hora.
Una vez elegido el tipo de bot, el siguiente paso era decidir qué mensaje iba a enviar: canciones, recomendaciones, restaurantes, vuelos... Estuve pensando en varias opciones, pero siempre terminaba en el mismo punto: LOS DATOS. Existen diferentes tipos de datos y diferentes formas de obtenerlos, pero ¿por qué no usar algo 'Open Data' para mi bot?
Yo ya tenía algo de experiencia con los datos abiertos del Ayuntamiento de Bilbao, y tras repasar el catálogo existente, pensé que los datos que mejor se ajustaban a mi bot eran los de BilbonBizi. BilbonBizi es el sistema de alquiler de bicicletas municipal del Ayuntamiento de Bilbao, hace unos años desarrollé una aplicación para los relojes Pebble que te permitía consultar el estado de las estaciones y la disponibilidad de bicicletas, así que era un viejo conocido con el que me resultaba más fácil trabajar.
Los datos provienen del catálogo de datos abiertos del Ayuntamiento de Bilbao.
Para acceder a estos datos, el Ayuntamiento de Bilbao expone un archivo XML con los datos en tiempo real de cada estación. Ya tenía la cuenta de Twitter, los datos y lo que me faltaba era decirle al bot qué quería que escriba y cada cuánto tiempo. Tras mirar al detalle el archivo XML, opté por crear un bot estadístico general, es decir, que cada hora escribiría dos tweet con los datos generales del servicio en ese momento:
[El dato de bicicletas en circulación aparece con un * ya que no se puede obtener ese
dato de ningún sitio, por esa razón y basándome en <a href="http://bilbao.net/cs/Satellite?c=BIO_Noticia_FA&cid=1279160512593&language=es&pageid=3000005580&pagename=Bilbaonet%2FBIO_Noticia_FA%2FBIO_Noticia">este articulo publicado a principios
de año</a>, estoy teniendo en cuenta que el total de bicicletas disponibles son 250.
Posiblemente el número será inferior.]
Un script en PHP y una tarea programada en el servidor hacen que el bot escribe los mensajes automáticamente.
¿Cómo se hace esto? Se crea un tarea programada en el servidor que lance un script cada hora (de PHP en este caso), traduzca todo el archivo XML , cree los dos mensajes y los publique en la cuenta de Twitter.
Una vez está el bot en funcionamiento, ¿qué obtenemos? Un status del servicio BilbonBizi por hora.
Twitter está bien, es inmediato, pero una vez escrito el tweet se pierde la información o estás obligado a usar su API para recuperarla. Así que decidí modificar el script en PHP para que además de seguir escribiendo los tweets, fuera escribiendo en un documento TODOS los datos por hora y por estación.
Tener todos los datos fraccionados por horas nos permite ver deficiencias del servicio usando herramientas como Microsoft Excel.
Tras unos días, veo que el archivo aumenta de tamaño, voy capturando datos y más datos, ¿y para qué sirven?
Podrían servir para Business Intelligence, es decir, para transformar los datos en información, y la información en conocimiento.
Al tener todos los datos fraccionados en horas, tenemos la posibilidad de ver, por ejemplo, en qué horas, días y/o meses hay menos bicicletas disponibles, qué zonas tienen más actividad, en qué zonas se averían con mayor frecuencia, etc. A nivel práctico, estos datos pueden servir para tomar decisiones que mejoren el servicio con datos reales sin moverte tu ordenador.
También hay que tener en cuenta que este 'estudio' está basado SOLO en los datos capturados del XML; cruzándolos con otros, como por ejemplo el tiempo o recorrido por bicicleta (no están disponibles), obtendríamos más información, mayor conocimiento del servicio que ofrecemos y la toma de decisiones sería aún más eficaz y eficiente.
Después de capturar datos durante unos días, ya se pueden ver posibles mejoras (teóricas) del servicio con unas simples gráficas
Después de estar capturando datos cada hora desde el 1 de Septiembre, ¿cómo los vemos?
Se puede usar cualquier herramienta como Microsoft Excel o Google Sheets para ver los resultados. No es necesario irse a aplicaciones de pago como Tableau para poder procesar datos. Veamos unos ejemplos:
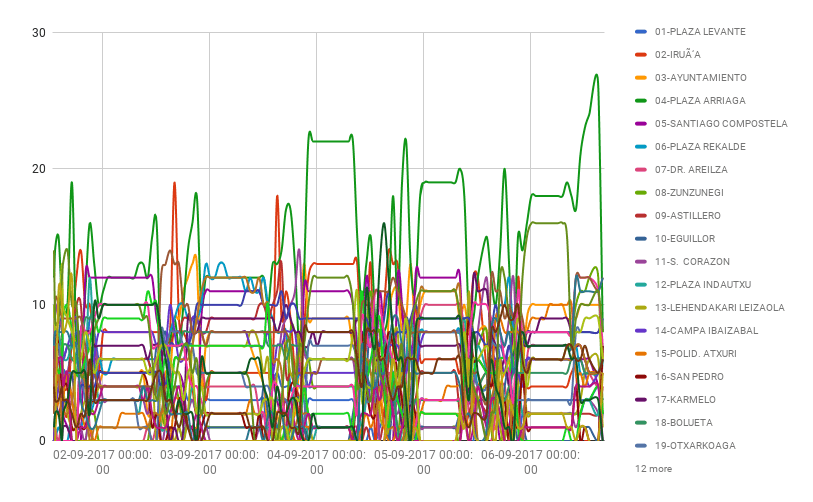
En el gráfico con todas las estaciones es complicado ver cosas, unicamente que Plaza Arriaga tiene a veces incluso 25 bicicletas libres.

En cambio si solo mostramos datos de una estación (Irala en este caso), podemos ver que ha pasado el fin de semana completo sin bicicletas o al menos, durante la semana se mueve en una horquilla de 0-6 bicicletas. A simple vista se aprecia que son necesarias más bicicletas en fin de semana.
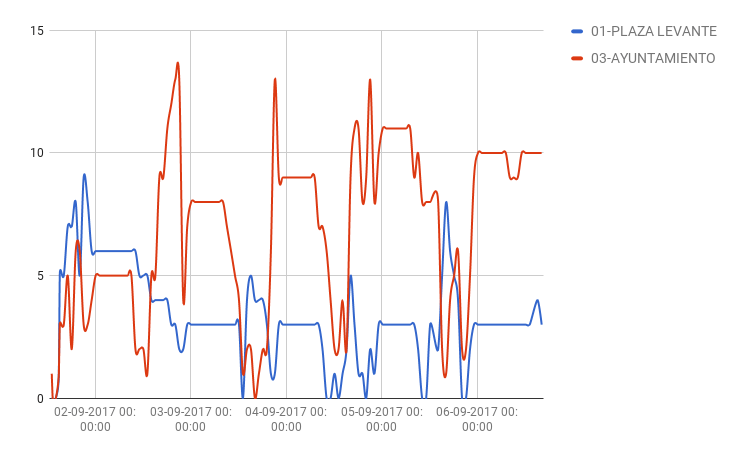
En este último gráfico de bicicletas libres podemos ver las gráficas de Plaza Levante y del Ayuntamiento. En el Ayuntamiento por las tardes la demanda aumenta y el uso del servicio en la Plaza Levante entre semana no permite que haya más de 5 bicicletas disponibles en ningún momento.
En cuanto a las bicicletas averiadas, los números que nos ofrece el ayuntamiento son complicados de entender. En general hay pocas bicicletas averiadas pero los números que ofrecen los datos nos dicen esto.
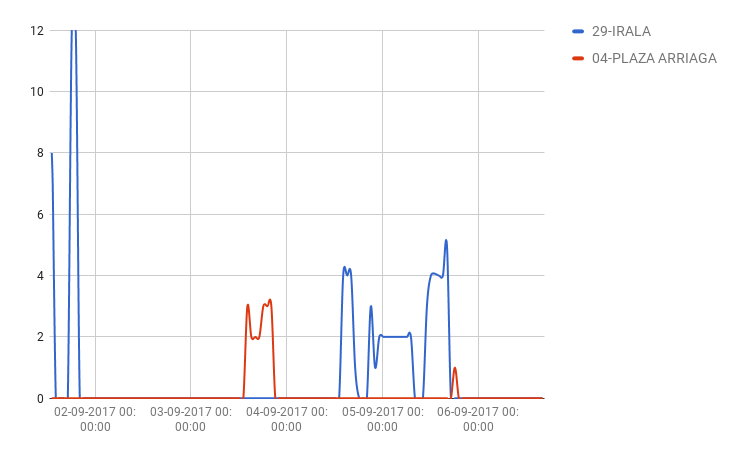
Por una parte tenemos la gráfica de Plaza Arriaga que es lógica, pequeños picos de bicicletas averiadas solucionadas en horas. El caso extraño es el de Irala que tiene picos de 12 bicicletas averiadas y solucionadas en una hora. Extraño.
Esto es solo una pequeña muestra de lo que se puede hacer con datos abiertos, un bot y un poco de tecnología.
Un saludo.